作者:琰琰 大规模深度神经网络训练仍是一项艰巨的挑战,因为动辄百亿、千亿参数量的语言模型,需要更多的 GPU 内存和时间周期。这篇文章从如何多GPU训练大模型的角度,回顾了现有的并行训练范式,以及主流的模型架构和内存优化设计方法。 “炼大模型”已成为人工智能领域的主流研发趋势。从GPT-3的1750亿,到如今悟道2.0的1.75万亿,超大语言模型在 NLP 基准任务中不断刷新SOTA。 然而,参数和数据集的快速增长让 GPU 算力开始捉襟见肘。单个GPU内存已经远远不能满足大模型的需求。如,阿里用480块GPU训练千亿模型;英伟达用3072块GPU训练万亿模型;谷歌用2048块TPU训练1.6万亿模型(1 TPU约等于2~3 GPU)。 如何利用上百块GPU上训练大规模语言模型?并行计算是一种行之有效的方法。 近日,OpenAI 研究员Lilian Weng分享干货文章,从并行训练(数据并行、模型并行、管道并行、张量并行)、混合专家、内存节省设计(CPU卸载、重新激活计算、混合精度训练、高效存储优化器)三个方面回顾了现阶段多GPU训练大模型的主流方法。 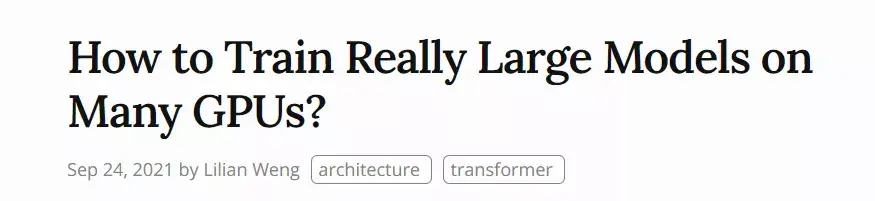 AI科技评论这篇文章编译如下,供想成为“炼丹师”的朋友参考。 1 并行训练大规模神经网络模型对存储空间有强烈的需求,单个GPU的内存已经远远不够。究其原因,一方面模型权重有数百亿个浮点数,随机梯度下降和Adam优化需要极高的计算成本;另一方面在预训练阶段,大模型与大规模语料库的配对需要很长的时间周期。综合来看,跨GPU并行计算显得尤为重要。 并行计算在数据、模型架构和张量等不同维度上都可以操作,接下来本文将具体介绍一些主流方法: 数据并行数据并行( Data parallelism ,DP)最简单的方法是将相同的模型权重复制到worker节点,并分配一部分数据以同时进行处理。我们知道,如果模型的参数量大于单个GPU节点的内存,DP无法正常工作,GeePS架构(Cui等人,2016)的解决思路是使用有限的GPU内存。也就是,如果模型太大无法嵌入到一台机器,就将暂时未使用的参数卸载回CPU。 数据交换传输通常在后端进行(不干扰训练计算),在每个Mini-batch计算结束后,worker需要同步梯度或权重,以保证学习效率。现有的同步方法有两种,各自优缺点如下: 1、批量同步并行(BSP):worker在每个Mini-batch结束时同步数据,这种方法保证了模型权重传递的及时性,但每台机器都必须排队等待其他机器发送梯度。 2、异步并行(ASP):每个GPU采用异步方式处理数据,这种方法避免了不同机器之间的相互等待或暂停,但影响了权重传递的时效,降低了统计学习效率。而且即使增加计算时长,也不会加快训练的收敛速度。 在中间某些地方的每一次迭代(>1)都需要同步全局梯度。自Pytorch v1.5版(Li等人,2021年)提出后,该特征在分布式数据并行(Distribution Data Parallel,DDP)中被称为“梯度累积(gradient accumulation)”。分桶梯度(bucketing gradients)避免立即执行AllReduce操作,而是将多个梯度存储到一个AllReduce中以提高吞吐量,并基于计算图优化计算和通信调度。  图1:Pytorch DDP的伪代码(来源:Li等人,2021年) 模型并行模型并行(Model parallelism,MP)用于解决模型权重不能适应单个节点的情况,在这里,计算和模型参数都需要跨多台机器进行处理。在数据并行中,每个worker承载着整个模型的完整副本,而MP只在一个worker上分配部分模型参数,因此对内存和计算的需求要小很多。 深度神经网络包含一堆垂直层,如果逐层拆分将连续的小层分配到工作层分区,操作起来并不难,但通过大量具有顺序依赖性的Workers来运行每个数据batch会花费大量的时间,计算资源的利用率也严重不足。 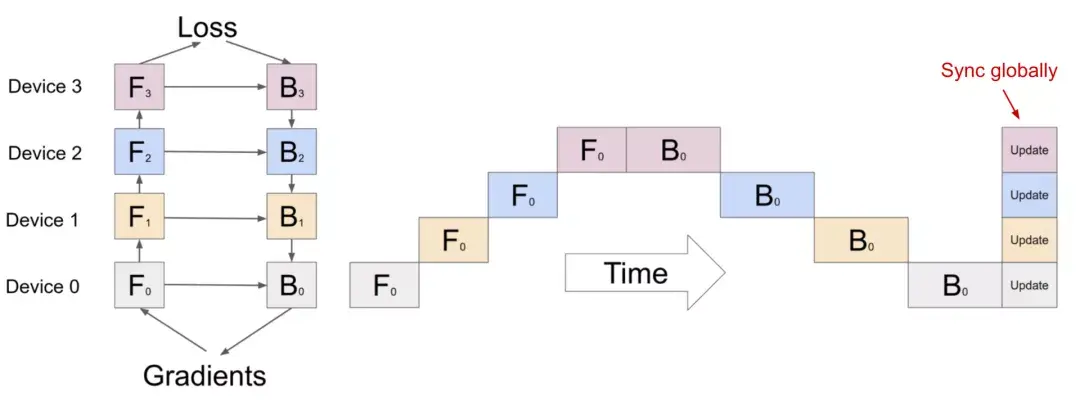 图2:一个包含4个垂直层的模型并行设置,由于顺序的依赖性,每个数据依次由一个worker处理,这个过程会出现大量多余时间“气泡”(来源:Huang等人,2019年) 管道并行管道并行(Pipeline parallelism,PP)是将模型并行与数据并行结合起来,以减少低效时间“气泡”的过程。主要思想是将Mini-batch拆分为更多个微批次(microbatch),并使每个阶段worker能够同时处理。需要注意的是,每个微批次需要两次传递,一次向前,一次向后。worker分区的数量称为管道深度,不同worker分区之间的通信仅传输激活(向前)和梯度(向后)。这些通道的调度方式以及梯度的聚合方式在不同的方法中有所不同。 在GPipe(Huang et al.2019)方法中,多个微批次处理结束时会同时聚合梯度和应用。同步梯度下降保证了学习的一致性和效率,与worker数量无关。如图3所示,“气泡”依旧存在,但比图2少了很多。给定m个均匀分割的微批次和d个分区,假设每个微批次向前和向后都需要一个时间单位,则气泡的分数为: 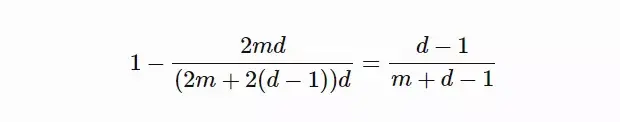 GPipe论文表明,如果微批次的数量超过分区数量4倍(m>4d),则“气泡”开销几乎可以忽略不计。 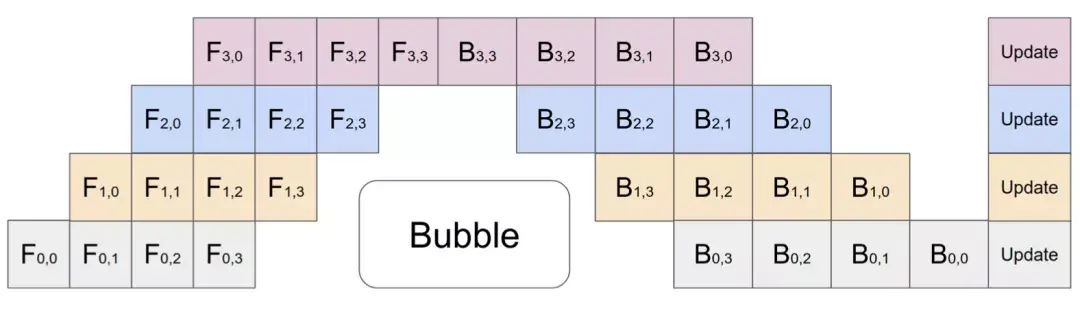 图3:带有4个微批次 和4个分区的GPipe的并行管道(来源:Huang等人,2019年) GPipe在吞吐量方面与设备数量成线性关系,设备数量越多,吞吐量越大。不过,如果模型参数在worker中分布不均匀,这种线性关系不会稳定出现。 PipeDream(Narayanan等人,2019年)方法要求每个worker交替处理向前和向后传递的消息(1F1B)。它将每个模型分区命名为“stage”,每个stage worker可以有多个副本来并行运行数据。这个过程使用循环负载平衡策略在多个副本之间分配工作,以确保相同minibatch 向前和向后的传递发生在同一副本上。 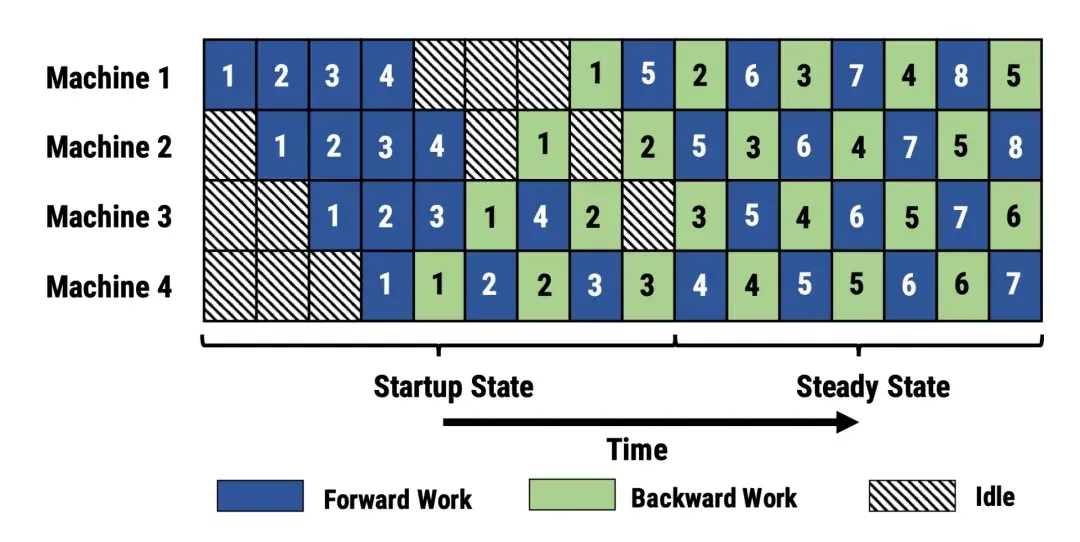 图4:PipeDream中1F1B微批次调度的图示(来源:Harlap等人,2018年) 由于PipeDream没有在所有worker batch结束时同步全局梯度,1F1B 很容易导致不同版本的模型权重的微批次向前和向后传递,降低学习效率。对此,PipeDream提供了一些解决的思路:
在训练开始时,PipeDream会先分析模型每一层的计算内存和时间成本,然后将层划分为不同的stage进行优化。 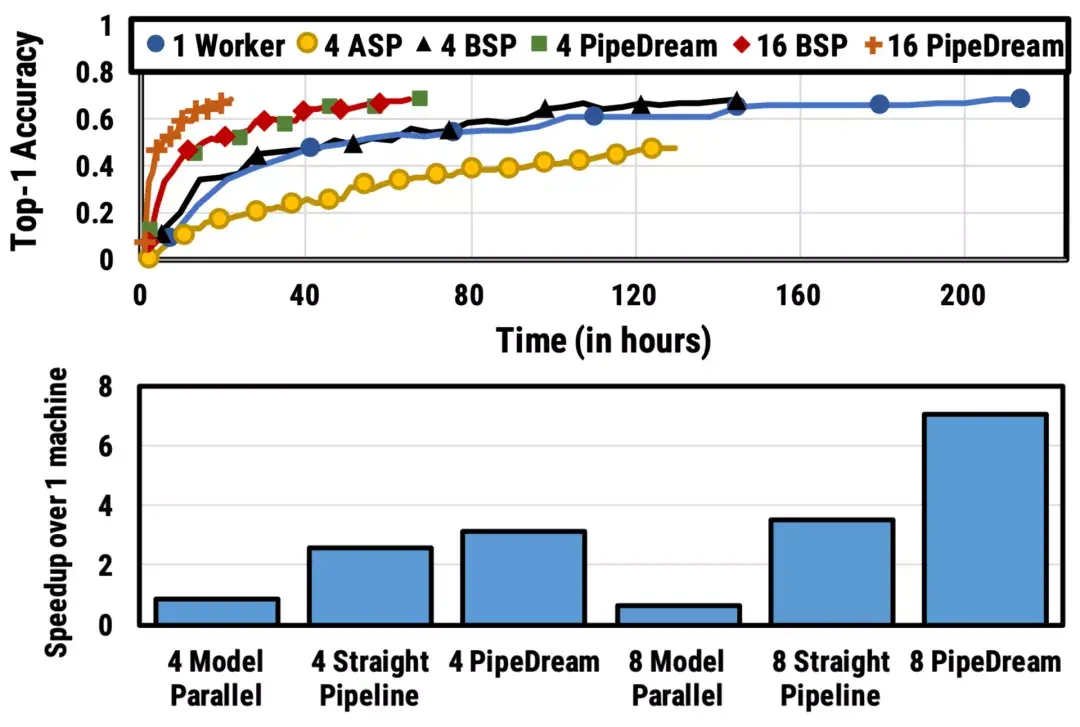 图5:上图为VGG16在ILSVRC12上的运行结果,ASP=异步并行,BSP=批量同步并行;下图为不同并行配置的训练时间加速度(来源:Harlap等人,2018年) 后来有学者提出了PipeDream两种变体,主要思路是通过减少模型版本来缓解内存占用(Narayanan等人,2021年)。其中,PipeDream-flush增加了定期刷新全局同步管道的功能,就像GPipe一样,这种方式虽然牺牲了一点吞吐量,但显著减少了内存占用(例如仅需要维护单一版本的模型权重)。 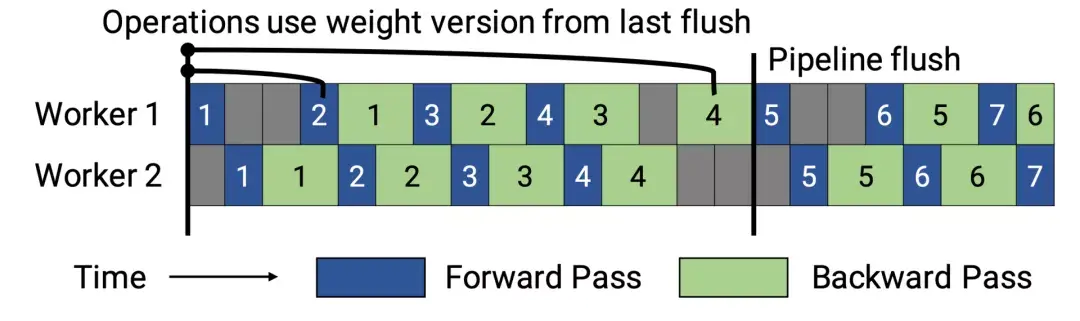 图6:PipeDream flush中管道调度图示(来源:Narayanan等人,2021年) PipeDream-2BW维护两个版本的模型权重,“2BW”代表“双缓冲权重(double-buffered weights)”,它会在每个微批次生成一个新的模型版本K(K>d)。由于一些剩余的向后传递依旧依赖于旧版本,新的模型版本无法立即取代旧版本,但因为只保存了两个版本,内存占用的也被大大降低了。 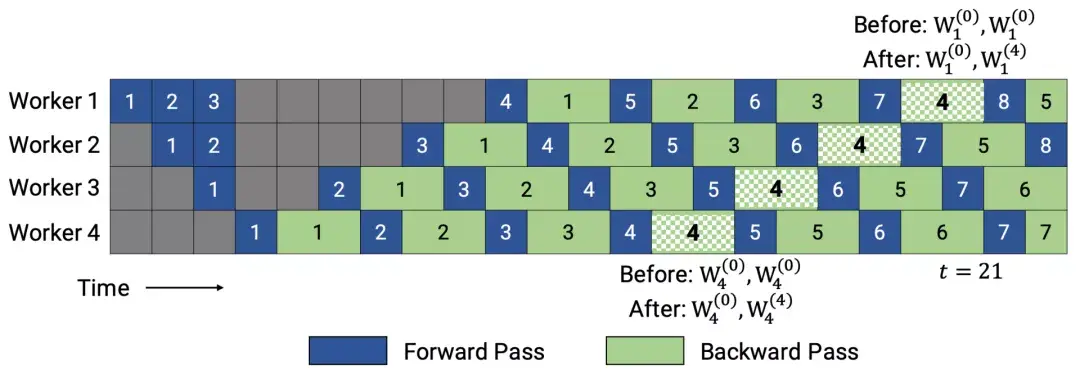 图7:PipeDream-2BW 中的流水线调度示意图(来源:Narayanan et al. 2021 张量并行 模型并行和管道并行都会垂直拆分模型,而张量并行(Tensor Parallelism,TP)是将张量运算的计算水平划分到多个设备上。 以Transformer为例。Transformer架构主要由多层MLP和自注意力块组成。Megatron-LM(Shoeybi et al.2020)采用了一种简单的方法来并行计算层内MLP和自注意力。 MLP层包含GEMM(通用矩阵乘法)和非线性GeLU传输。如果按列拆分权重矩阵A,可以得到:  注意力块根据上述分区并行运行GEMM的 查询(Q)、键(K)和 权重(V),然后与另一个GEMM组合以生成头注意力结果。 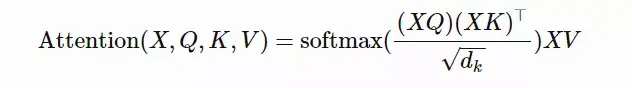 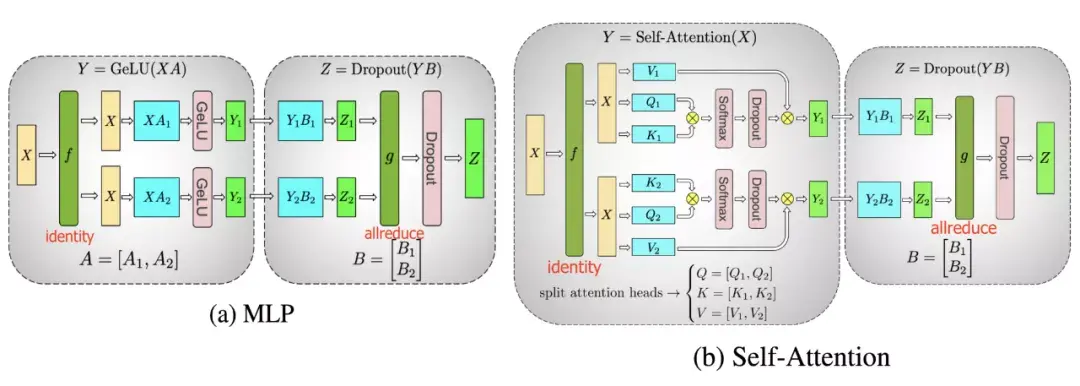 图8:Megatron-LM中提出的关键Transformer组件的张量平行性说明。(来源:Shoeybi等人,2020年) 今年Narayanan等人将管道、张量和数据并行与新的管道调度策略相结合,提出了一种名为PTD-P的新方法。该方法不仅在设备上能够定位一组连续的层(“模型块”),该可以为每个wokers分配多个较小的连续层子集块(例如,设备1具有第1、2、9、10层;设备2具有第3、4、11、12层;每个具有两个模型块) 每个batch中,微批次的数量应精确除以wokers数量(mm)。如果每个worker有v个模型块,那么与GPipe调度相比,管道的“气泡”时间可以减少 v 倍。 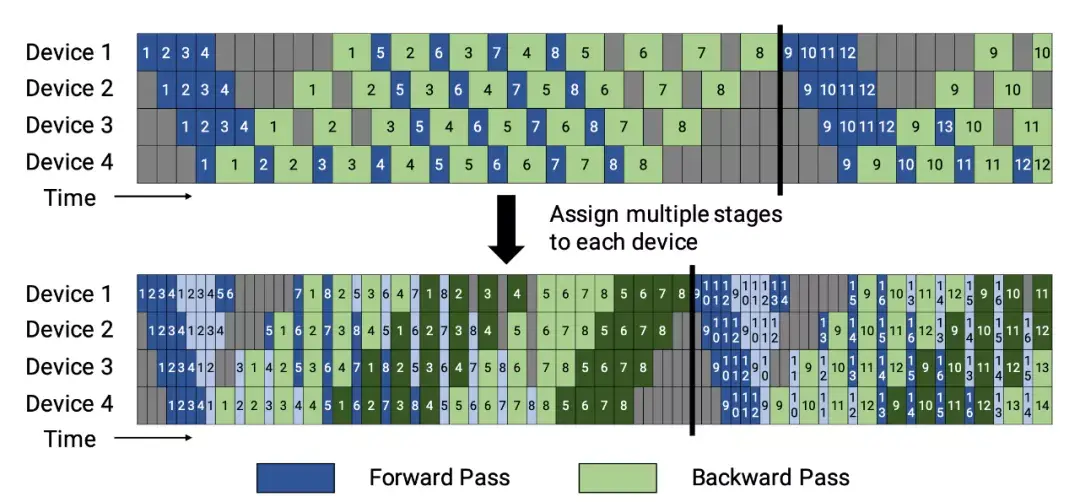 图9:上图与PipeDream flush中的默认1F1B管道明细表相同;下图为交错的1F1B管线一览表(来源:Narayanan等人,202) 2 混合专家(MoE)为了突破模型大小的限制,谷歌后来提出一种混合专家(MoE)方法,其核心理念是:综合学习,它假设多个弱学习者组合起来就会拥有一个强学习者。 在深度神经网络中,混合专家(MoE)通过连接多个专家的门机制(gating mechanism)实现集成(Shazeer等人,2017)。门机制激活不同网络的专家以产生不同的输出。作者在论文将其命名为“稀疏门控专家混合层(sparsely gated MoE)”。 仅一个MoE层包含:(1)前馈网络专家n;(2)可训练的门控网络G,通过学习n个专家的概率分布,将流量路由到几个特定的专家。 根据门控输出,并非每个专家都必须进行评估。当专家的数量太大时,可以考虑使用两层MoE。 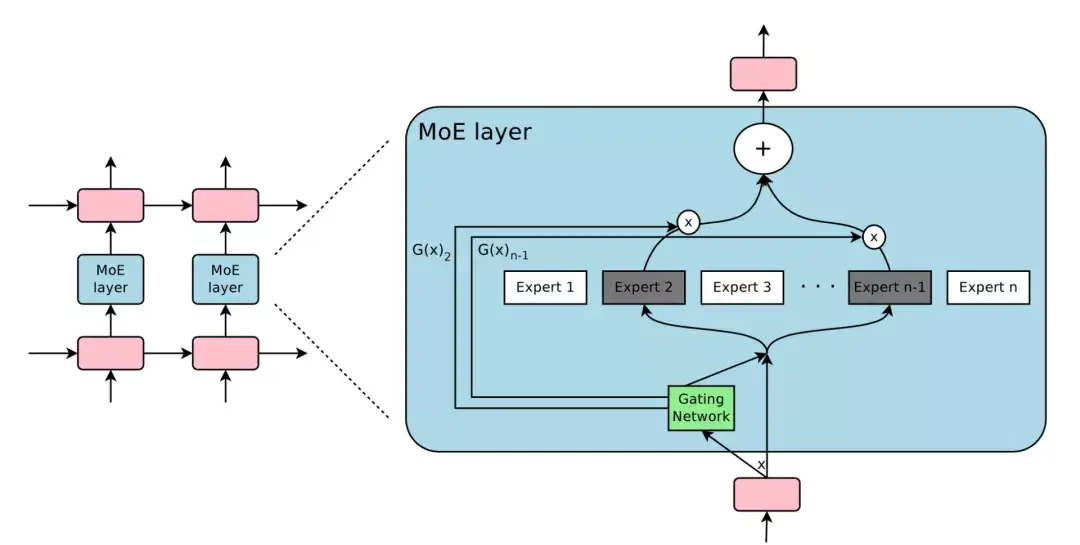 图10:专家混合(MoE)层的图示,门控网络只选择并激活了n个专家中的2个(来源:Shazeer等人,2017年) G将输入与可训练权重矩阵Gg相乘,然后执行softmax: 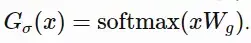 由于这个过程会产生密集的门控制向量,不利于节省计算资源,而且 G^{(i)}(x)=0 时也不需要评估专家。所以,MoE层仅保留了顶部k值,并通过向G中添加高斯噪声改进负载平衡,这种机制被称为噪声top-k门。  为了避免门控网络可能始终偏向少数强势专家的自我强化效应,Shazeer等人(2017)提出了通过额外重要损失的软约束,以鼓励所有专家拥有相同的权重。其数值相当于每个专家的分批平均值变异系数的平方: 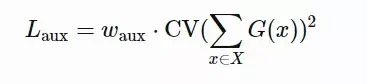 其中,CV是变异系数,失重的waux是可调节的超参数。由于每个专家网络只能获得小部分训练样本(“收缩批次问题”),所以在MoE中应该尽可能使用大batch,但这又会受到GPU内存的限制。数据并行和模型并行的应用可以提高模型的吞吐量。 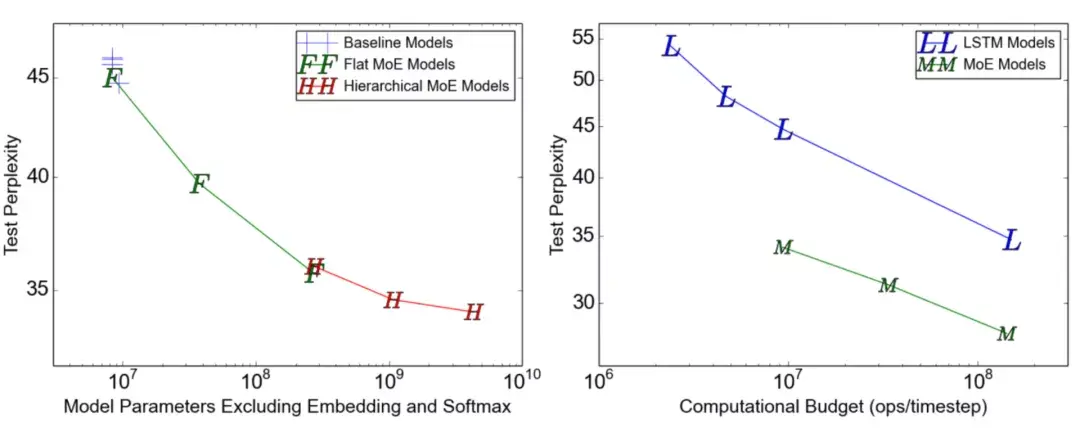 图11:10亿单词的语言建模基准(左)模型从左到右包含4、32、256、256、1024和4096名专家(右)40亿参数的MoE模型在不同计算预算下的性能(来源:Shazeer等人,2017年) GShard(Lepikhin等人,2020年)通过自动分片将MoE transformer 模型的参数扩展到了6000亿。MoE transformer 用MoE层取代其他每一个前馈网络层。需要说明的是,在多台机器上MoE transformer 仅在MoE层分片,其他层只是复制。 GShard中的门控功能G有几种改进设计:
 图12:GShard中带辅助损失的组水平top-2门机制的伪代码(来源:Lepikhin等人,2020年) Switch Transformer(Fedus et al.2021)用稀疏开关FFN层取代了密集前馈层(每个输入仅路由到一个专家网络),将模型规模扩展到数万亿个参数。负载平衡的辅助损失是 \operatorname{loss}_{\mathrm{aux}}=w_{\mathrm{aux}} \sum_{i=1}^{n} f_{i} p_{i} ,给定n个专家,fi是路由到第i个专家的令牌分数,pi是门控网络预测的专家i的路由概率。 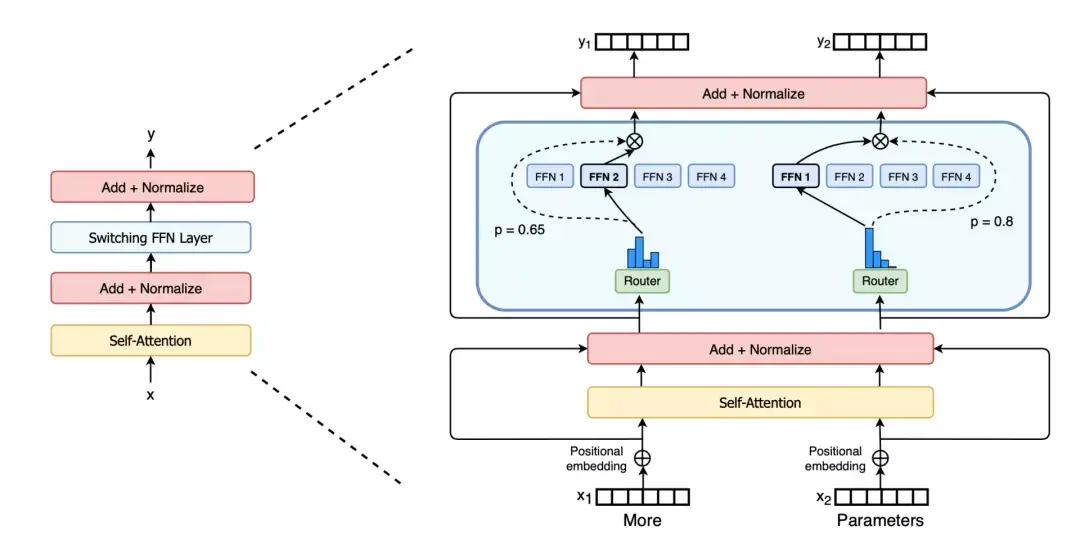 图13:Switch transformer,稀疏Switch FFN层位于蓝色框(来源:Fedus等人,2021年) 为提高训练稳定性,switch transformer采用以下设计:
switch transformer论文总结了用于训练大型模型的不同数据和模型并行策略,并给出了一个很好的示例: 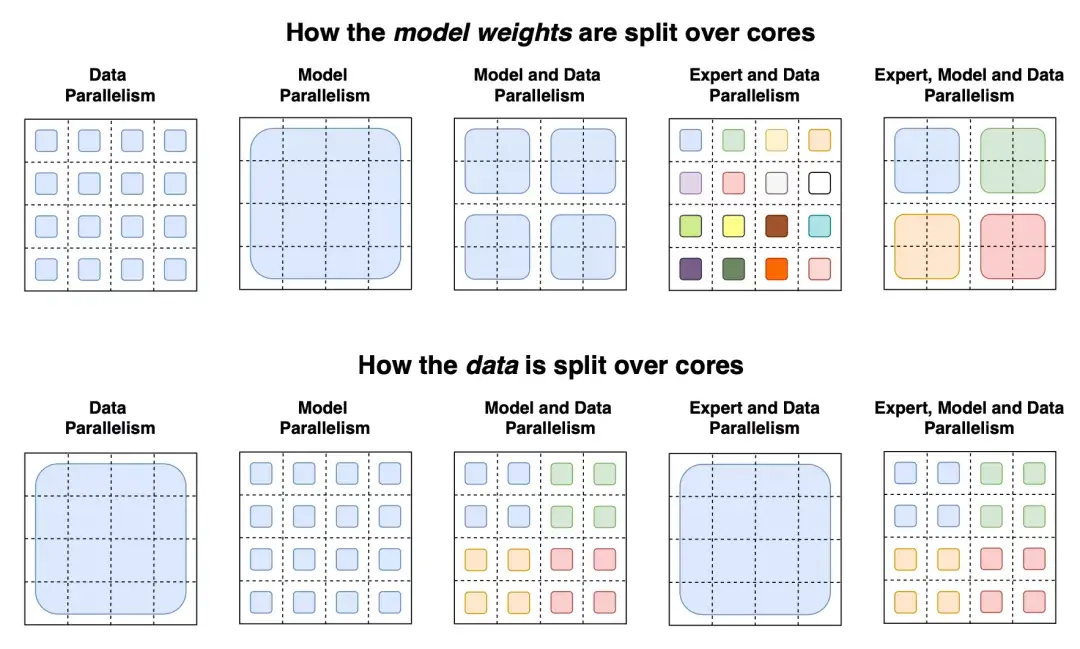 图14:第一行为如何在多个GPU内核拆分模型权重(顶部),每种颜色代表一个权重矩阵;第二行为各种数据并行策略的说明,不同颜色表示不同的标记集(来源:Fedus等人,2021年) 3 其他节省内存的设计CPU卸载如果GPU内存已满,可以将暂时未使用的数据卸载到CPU,并在以后需要时将其读回(Rhu等人,2016)。不过,这种方法近年来并不太流行,因为它会延长模型训练的时间。 激活重新计算激活重新计算,也称“激活检查点”或“梯度检查点”(Chen et al,2016),其核心思路是牺牲计算时间来换取内存空间。它减少了训练 层深层神经网络到 O(\sqrt{\ell}) 的内存开销,每个batch只消耗额外的前向传递计算。 具体来说,该方法将层网络平均划分为d个分区,仅保存分区边界的激活,并在workers之间进行通信。计算梯度依旧需要在分区内层进行中间激活,以便在向后过程中重新计算梯度。在激活重新计算的情况下,用于训练M() 是:  它的最低成本是: 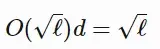 激活重新计算的方法可以得出与模型大小有关次线性内存开销,如下图: 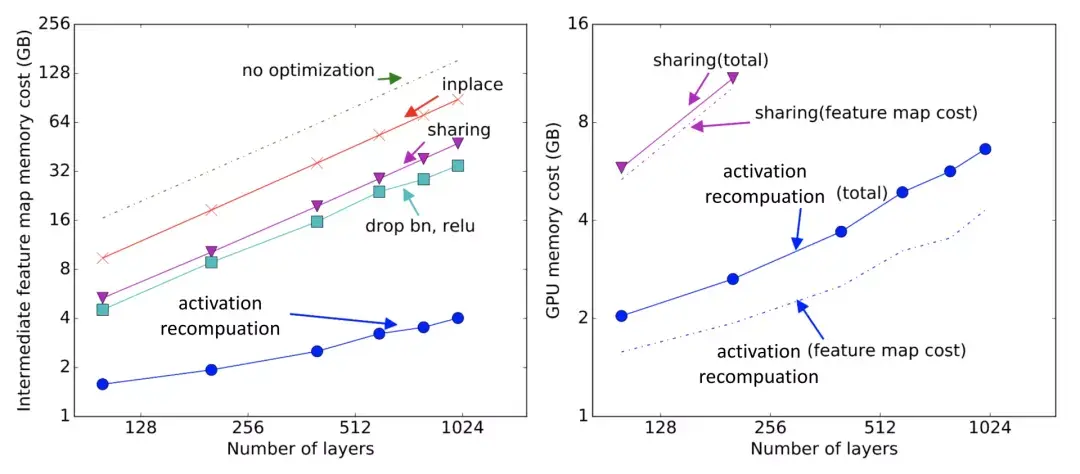 图15:不同节省内存算法的内存开销。sharing:中间结果使用的内存在不再需要时被回收。inplace:将输出直接保存到输入值的内存中(来源:Chen等人,2016) 混合精度训练此前,Narang(Narang&Micikevicius等人,2018年)介绍了一种使用半精度浮点(FP16)数训练模型而不损失模型精度的方法。 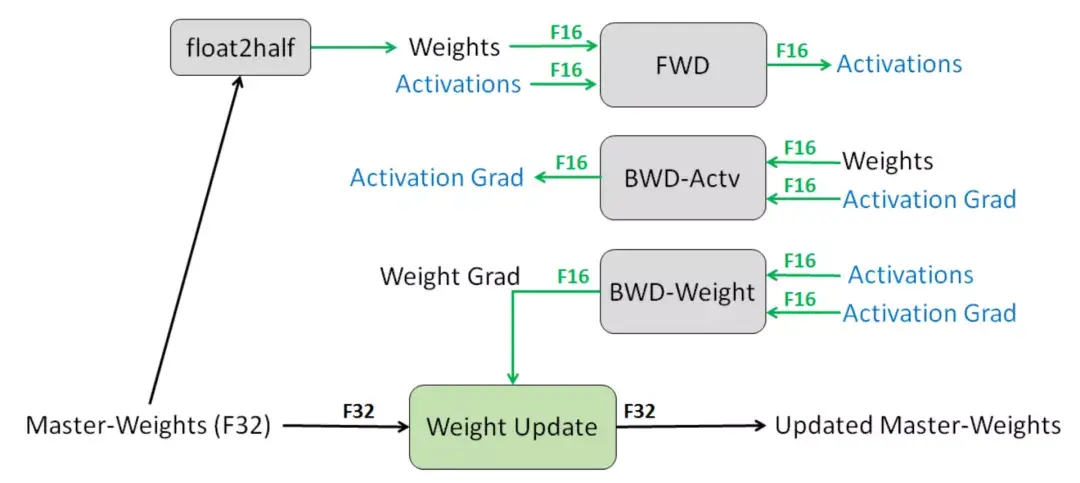 图16:一层混合精度训练程序(来源:Narang&Micikevicius等人,2018年) 其中涉及三种关键技术:
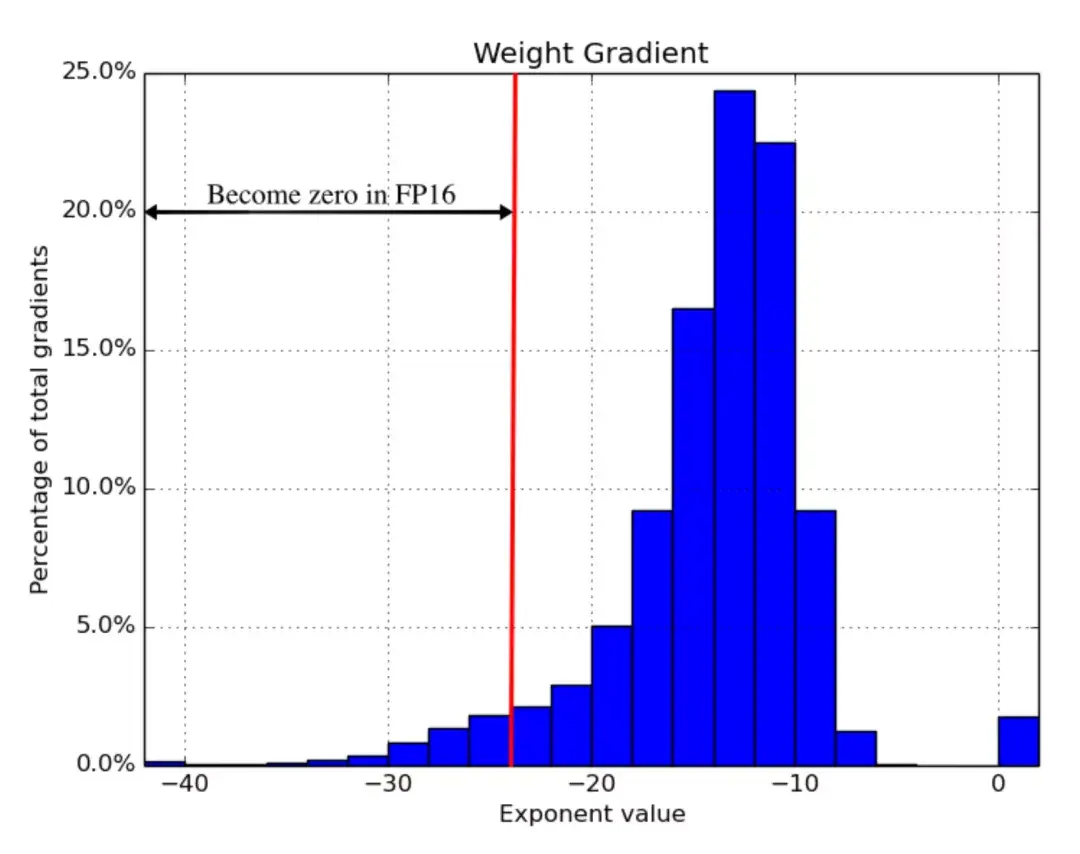 图17:全精确的梯度直方图 在这项实验中,图像分类、更快的R-CNN等不需要损失缩放,但其他网络,如多盒SSD、大LSTM语言模型是需要损失缩放的。 压缩(Compression)模型权重在向前和向后传递的过程中会消耗大量内存。考虑到这两种传递方式会花费大量时间,2018年Jain (Jain et al,2018)提出了一种数据编码策略,即在第一次传递后压缩中间结果,然后将其解码用于反向传播。 Jain和团队研发的Gist系统包含两种编码方案:一是特定于层的无损编码,包括 ReLU-Pool和 ReLU-Conv模式;二是有攻击性的有损编码,主要使用延迟精度缩减(DPR)。需要注意的是,第一次使用特征图时应保持高精度,第二次使用时要适度降低精度。这项实验表明,Gist可以在5个最佳图像分类DNN上减少2倍的内存开销,平均减少1.8倍,性能开销仅为4%。 内存高效优化器优化器也会消耗内存。以主流的Adam优化器为例,其内部需要维护动量和方差,这两者与梯度和模型参数比例基本相同。这意味着,我们需要节省4倍模型权重的内存。 为了减少内存消耗,学术界已经提出了几款主流优化器。与Adam相比,Adafactor(Shazeer et al.2018)优化器没有存储全部动量和变化,只跟踪移动平均数的每行和每列总和,然后根据这些总和估计二阶矩。 SM3(Anil et al.2019)优化器采用了一种不同的自适应优化方法。 ZeRO(Rajbhandari et al.2019)零冗余优化器节省了大型模型训练在两方面的内存消耗:
ZeRO结合了ZeRO-DP和ZeRO-R两种方法。ZeRO-DP是一种增强的数据并行,避免了模型状态的简单冗余。它以动态的方式跨多个并行数据划分优化器状态、梯度和参数,以最小化通信量。ZeRO-R使用分区激活二次计算、恒定缓冲区大小和动态内存碎片,以优化剩余状态的内存消耗。 参考资料: [1] Li et al. “PyTorch Distributed: Experiences on Accelerating Data Parallel Training” VLDB 2020. [2] Cui et al. “GeePS: Scalable deep learning on distributed GPUs with a GPU-specialized parameter server” EuroSys 2016 [3] Shoeybi et al. “Megatron-LM: Training Multi-Billion Parameter Language Models Using Model Parallelism.” arXiv preprint arXiv:1909.08053 (2019). [4] Narayanan et al. “Efficient Large-Scale Language Model Training on GPU Clusters Using Megatron-LM.” arXiv preprint arXiv:2104.04473 (2021). [5] Huang et al. “GPipe: Efficient Training of Giant Neural Networks using Pipeline Parallelism.” arXiv preprint arXiv:1811.06965 (2018). [6] Narayanan et al. “PipeDream: Generalized Pipeline Parallelism for DNN Training.” SOSP 2019. [7] Narayanan et al. “Memory-Efficient Pipeline-Parallel DNN Training.” ICML 2021. [8] Shazeer et al. “The Sparsely-Gated Mixture-of-Experts Layer Noam.” arXiv preprint arXiv:1701.06538 (2017). [9] Lepikhin et al. “GShard: Scaling Giant Models with Conditional Computation and Automatic Sharding.” arXiv preprint arXiv:2006.16668 (2020). [10] Fedus et al. “Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity.” arXiv preprint arXiv:2101.03961 (2021). [11] Narang & Micikevicius, et al. “Mixed precision training.” ICLR 2018. [12] Chen et al. 2016 “Training Deep Nets with Sublinear Memory Cost.” arXiv preprint arXiv:1604.06174 (2016). [13] Jain et al. “Gist: Efficient data encoding for deep neural network training.” ISCA 2018. [14] Shazeer & Stern. “Adafactor: Adaptive learning rates with sublinear memory cost.” arXiv preprint arXiv:1804.04235 (2018). [15] Anil et al. “Memory-Efficient Adaptive Optimization.” arXiv preprint arXiv:1901.11150 (2019). [16] Rajbhandari et al. “ZeRO: Memory Optimization Towards Training A Trillion Parameter Models Samyam.” arXiv preprint arXiv:1910.02054 (2019). 编译链接:https://lilianweng.github.io/lil-log/2021/09/24/train-large-neural-networks.html
已建立机器学习算法-自然语言处理微信交流群!想要进交流群进行学习的同学,可以直接加我的微信号:HIT_NLP。加的时候备注一下:知乎+学校+昵称 (不加备注不会接受同意,望谅解),想进pytorch群,备注知乎+学校+昵称+Pytorch即可。然后我们就可以拉你进群了。群里已经有非得多国内外高校同学,交流氛围非常好。 强烈推荐大家关注机器学习算法与自然语言处理账号和机器学习算法与自然语言处理微信公众号,可以快速了解到最新优质的干货资源。 推荐阅读每日论文速递:自然语言处理相关(10月6日更新版) - 知乎 (zhihu.com) 每日论文速递:计算机视觉相关(10月5日更新版) - 知乎 (zhihu.com) 每日论文速递:自然语言处理相关(10月5日更新版) - 知乎 (zhihu.com) 新加坡国立大学WING实验室信息检索及知识组织研讨会即将召开! - 知乎 (zhihu.com) 博士后招聘 | 湖南大学刘敏教授课题组诚聘模式识别、计算机视觉和机器人相关研究领域博士后/教师 - 知乎 (zhihu.com) 2021年了!NLP模型该学会因果推理了! - 知乎 (zhihu.com) DeepMind带飞! - 知乎 (zhihu.com) 实习/博士申请 | 香港中文大学(深圳)招收实习生及博士,医学影像分析领域 - 知乎 (zhihu.com) 数学教育中的AI:NeurIPS’21 Workshop 欢迎投稿! - 知乎 (zhihu.com) 每日论文速递:计算机视觉相关(10月4日更新版) - 知乎 (zhihu.com) 每日论文速递:自然语言处理相关(10月4日更新版) - 知乎 (zhihu.com) 校招黑名单 - 知乎 (zhihu.com) 仅靠合成数据就能实现真实人脸分析!微软这项新研究告别人工标注 - 知乎 (zhihu.com) 如何检测两组数据是否同分布? - 知乎 (zhihu.com) 让你的模型acc更上一层楼:模型trick和数据方法总结 - 知乎 (zhihu.com) 用上Pytorch Lightning的这六招,深度学习pipeline提速10倍! - 知乎 (zhihu.com) 博士申请 | 全奖博士招生,伊利诺伊理工大学计算机系 - 知乎 (zhihu.com) 你已经是一个成熟的NLP模型了,该学会处理长文本了! - 知乎 (zhihu.com) 再登Nature!从玻璃箱的水流到200万平方公里的降雨预报,DeepMind的AI物理模拟上天了 - 知乎 (zhihu.com) 第二十七届全国信息检索学术会议(CCIR2021)开放注册 - 知乎 (zhihu.com) 招聘 | 阿里巴巴达摩院NLP研究科学家——语言技术实验室——多语言NLP团队 - 知乎 (zhihu.com) 2600star!Pytorch代码实现斯坦福CS224N课程模型!自然语言处理领域YYDS! - 知乎 (zhihu.com) NLP与CV大一统的尽头是语言模型?Hinton团队提出Pix2Seq做目标检测,性能抗打! - 知乎 (zhihu.com) 征稿 | 国际KG大会IJCKG 2021投稿延期!推荐 SCI 一区期刊 - 知乎 (zhihu.com) 每日论文速递:自然语言处理相关(9月30日更新版) - 知乎 (zhihu.com) 每日论文速递:计算机视觉相关(9月30日更新版) - 知乎 (zhihu.com) ACL2021上的Dialogue 赛尔笔记 | 自然语言处理中模型的“偷懒” ICLR2021 | 近期必读图神经网络精选论文 - 知乎 (zhihu.com) AAAI 近20年最佳论文合集 - 知乎 (zhihu.com) NAACL 2021 | 对比学习横扫文本聚类任务 - 知乎 (zhihu.com) 不可错过!CMU「概率图模型」课程,附Slides - 知乎 (zhihu.com) ICCV 2021审稿结果出炉,有人已总结出了一份Rebuttal写作指南 - 知乎 (zhihu.com) 腾讯优图+厦门大学发布!2021十大人工智能趋势 - 知乎 (zhihu.com) 2021下半年会议论文投稿时间小结与历年接受率回顾(欢迎收藏) - 知乎 (zhihu.com) PyTorch 常用代码段汇总 - 知乎 (zhihu.com) Transformer长大了,它的兄弟姐妹们呢?(含Transformers超细节知识点) - 知乎 (zhihu.com) Transformer Decoder-Only 模型批量生成 Trick - 知乎 (zhihu.com) 第十届全国社会媒体处理大会(SMP 2021) 技术评测方案 - 知乎 (zhihu.com) 首篇NLP图神经网络综述来了! 127页文档让你全面了解这个领域 - 知乎 (zhihu.com) Transformer杀疯了!竟在图神经网络的ImageNet大赛中夺冠,力压DeepMind、百度...... - 知乎 (zhihu.com) 深度学习中的Attention总结 - 知乎 (zhihu.com) ICLR/CVPR时间更新 || 2021下半年会议论文投稿时间小结与历年接受率回顾(欢迎收藏) - 知乎 (zhihu.com) 中科院软件所中文信息处理实验室招收2021年推免学生(硕博各2-3名) - 知乎 (zhihu.com) 一文掌握《对比学习(Contrastive Learning)》要旨,详述MoCo和SimCLR算法 - 知乎 (zhihu.com) 赛尔笔记|基于深度学习方法的对话状态跟踪综述 - 知乎 (zhihu.com) 一文速览 | ACL 2021 主会571篇长文分类汇总 - 知乎 (zhihu.com) Hugging Face官方NLP课程来了!Transformers库维护者之一授课,完全免费 - 知乎 (zhihu.com) ICML2021论文太多看不过来?这份《一句话点评1183篇论文亮点》帮你快速找到想看的 - 知乎 (zhihu.com) |

 万奢网手机版
万奢网手机版
官网微博:万奢网服务平台












