
为什么要学习编译原理
作为程序员,不论是前端开发工程师还是后端开发工程师,编译技术都与我们的工作息息相关。在实践工作中也经常会碰到需求编译技术的场景。好比,前端开发工程师想要了解Type是如何把一门言语翻译成另一门言语的,以及babel是如何编译Java的等等。 学习编译技术有助于提升我们的职场竞争力,更有助于程序员在技术的道路上走的更远。那么学习完本篇文章你会对编译原理有个初步的认识,好比:
- 知道为什么要学习编译
- 了解编译原理和我们日常开发中运用的开发言语的关系
- 了解编译在言语系统中所处的位置及 编译系统的结构
- 了解 词法剖析、语法剖析、语义剖析 这些我们工作中经常听到的概念等等
什么是编译原理 编译与计算机程序设计言语的关系
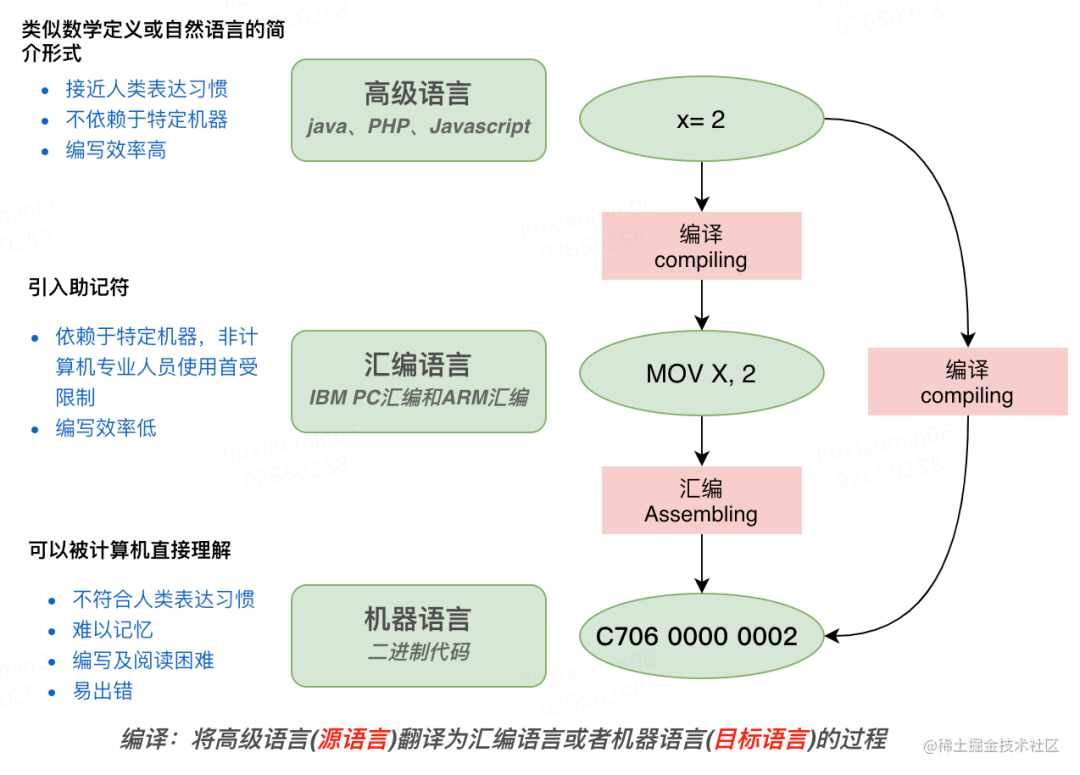
留意:每种机器都对应一种汇编言语
程序设计言语的转换方式
翻译:指把某种言语的源程序, 在不改动语义的条件下,转换成另一种言语程序即目的言语程序
真正的完成有两种方式,编译及解释
- 编译 :专指由高级言语转换为低级言语, 整个程序翻译 。常用的例如:c、c++,delphi,Fortran、Pascal、Ada
- 解释 :接受某种高级言语的一个语句输入,中止解释并控制计算机执行,马上得到这个句子的执行结果,然后再接受下一个语句。相似口译, 一句一句中止解释 。常用的例如:python 解释以源程序作为输入, 不产生目的程序 ,一边解释一边执行。 优点 :直观易懂,结构简单,易于完成人机对话。 缺陷 :效率低(不产生目的程序,每次都需求重新执行,速度慢)
编译的转换过程编译器在言语处置系统中的位置
了解了编译与程序设计言语的关系,那么我们接下来再来看下编译器在言语处置系统中所处位置,如下图 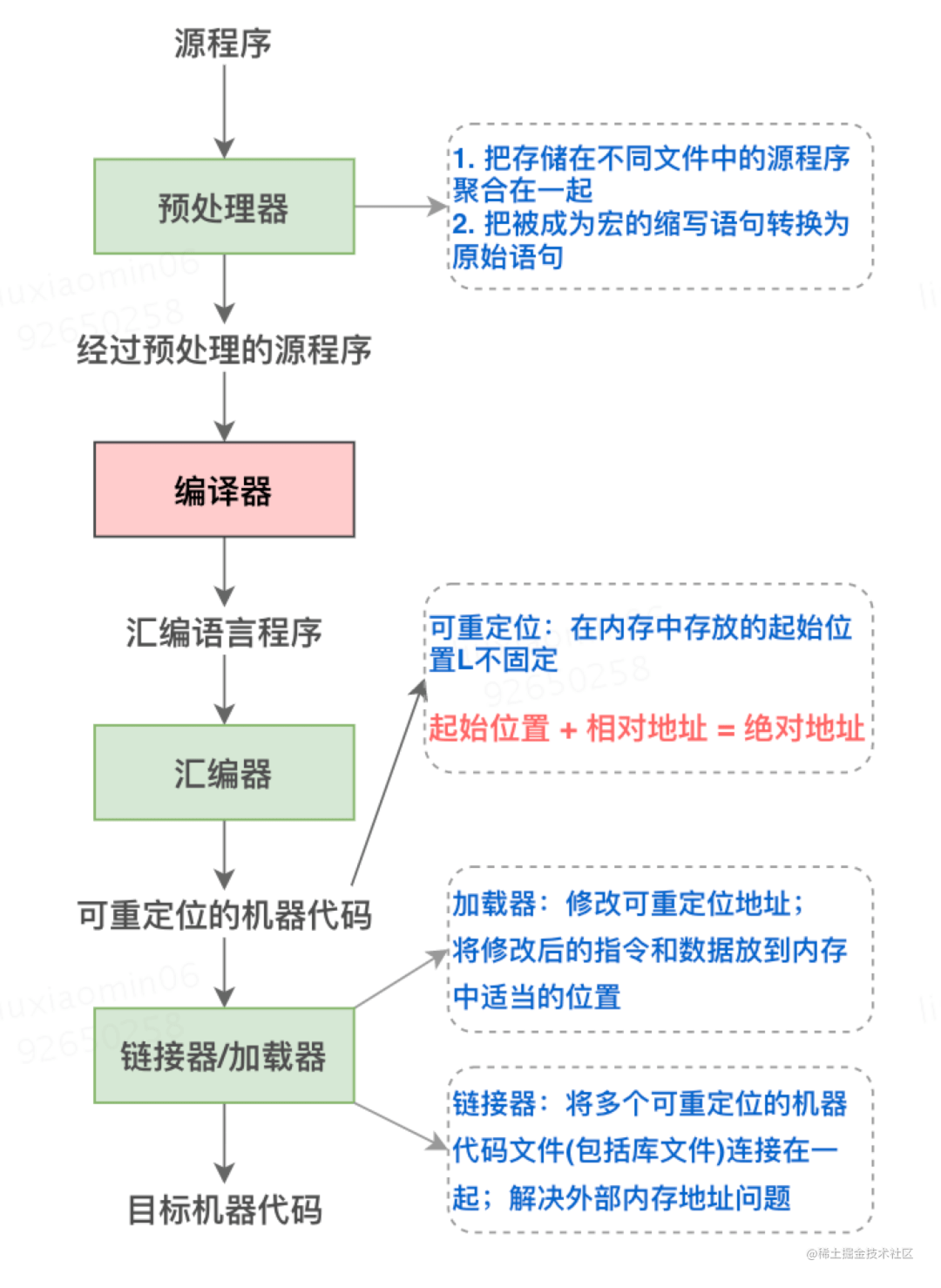
编译系统的结构
那么机器是如何把高级言语翻译为汇编言语程序或机器言语程序的呢?
我们先来看下人工中止英文翻译的例子,这里援用的哈工大编译原理中的图示 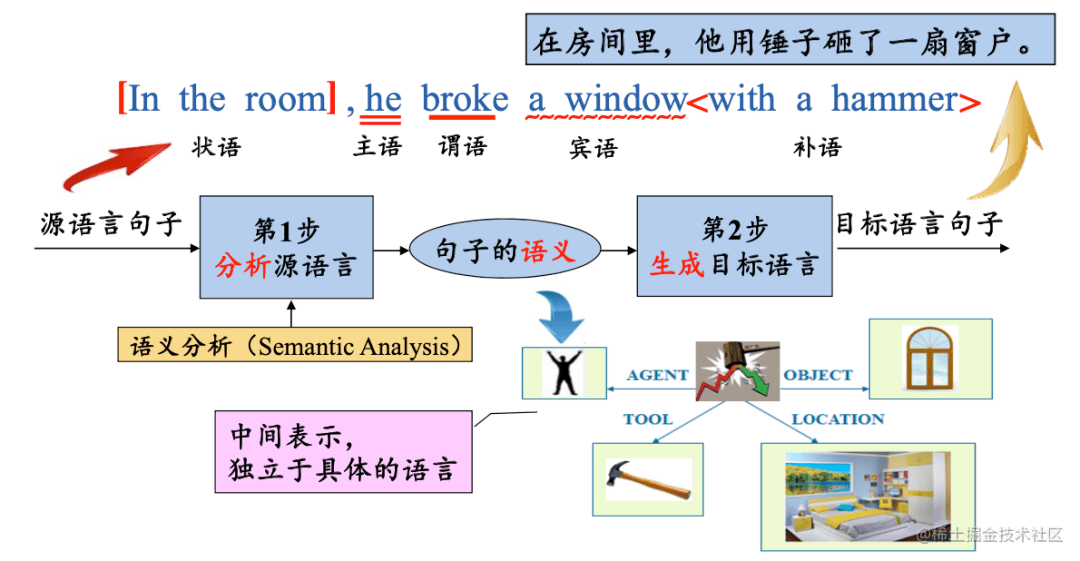
图中的 中间表示很重要主要起到了一个桥梁的作用,好比图中的中间表示能够运用各种言语表示。
依据上图能够看出要中止语义剖析首先需求划分句子成分,那么我们是如何划分句子成分的呢?
- 首先经过 词法剖析剖析出句子中各个单词的词性或者词类
- 然后中止 语义剖析依据句子结构剖析出句子中各个短语在句子中充任什么成分 ,从而肯定各个名词性成分同各个中心谓语动词间的关系语意关系
- 最后给出中间表示方式 实践上编译器在工作的时分也是经过了以上几个步骤,我们成为 阶段(计算机的逻辑组织方式,在完成过程中多个阶段可能会被组合在一同完成) ,能够分为两大部分: 剖析源言语、生成目的代码 ,在编译器中他们分别对应编译器的前端和后端两个部分。编译器的结构如下图 了解了编译器的结构,让我们从编译器的前端开端讲起,看看词法剖析、语法剖析、语义剖析等各个阶段都做了什么。
词法剖析(扫描)
t o k e n : < 种别码,属性值 > token:<种别码,属性值> 
名字解释
- 一词一码 :例如,关键字是独一的且事前能够肯定,为每个关键字分配一个种别码
- 多词一码 :例如,一切的标示符统一作为一类单词分配同一个种别码,为了分辨不同的标示符,用token的第二个重量“属性值”寄存不同标示符细致的字面值
- 一型一码 :不同类型的常量他们的构成方式是不同的,例如,我们为每种类型的常量分配一个种别码,为了分辨同一类型下的不同常量,也用token的第二个重量“属性值”寄存每个常量细致的值 下面图中是一个词法剖析后得到的token序列的例子 描画词法规则的有效工具是 正轨式 和 有限自动机 。 正轨式 :用来肯定单词能否和程序言语规范。 有限自动机 :经过有限自动机中止单词和正轨式比较
语法剖析(parsing) 语法剖析的定义
语法剖析的规则即 语法规则又称 文法,规则了单词如何构成短语、句子、过程和程序。
语法规则的标示如下,含义是A定义为B或者C
B N F : A : : = B ∣ C BNF: A::= B∣ <
句子 > : : = < 主 > < 谓 > < 宾 > <句子>::=<主><谓><宾>
< 主 > : : = < 定 > < 名 > <主>::=<定><名>
来看下赋值语句的语法规则:
- A::=V=E
- E::=T|E+T
- T::=F|T*F
- F::=V|(E)|C
- V::=标示符
- C::=常数 即由标示符或者常数的表白式中止加减乘除运算
语法剖析的措施
推导(derive)和归约(reduce)
- 推导 :最左推导、最右推导
- 归约 :最右归约、最左归约,推导的逆过程就是归约
最右推导、最左归约: 最左推导、最右归约:
语法树
计算机经过 语法树来中止剖析,即语法剖析过程也能够用一颗倒着的树来标示,这颗树叫 语法树。正确的语法树叶子节点数必须是表白式的符号,例如 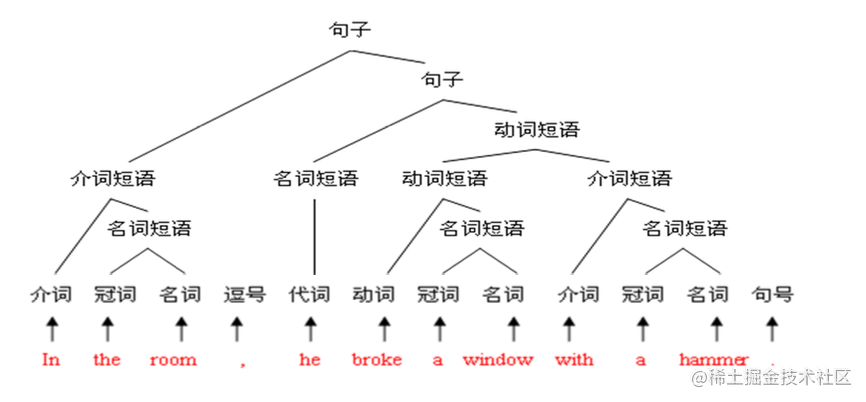
赋值语句的剖析树: 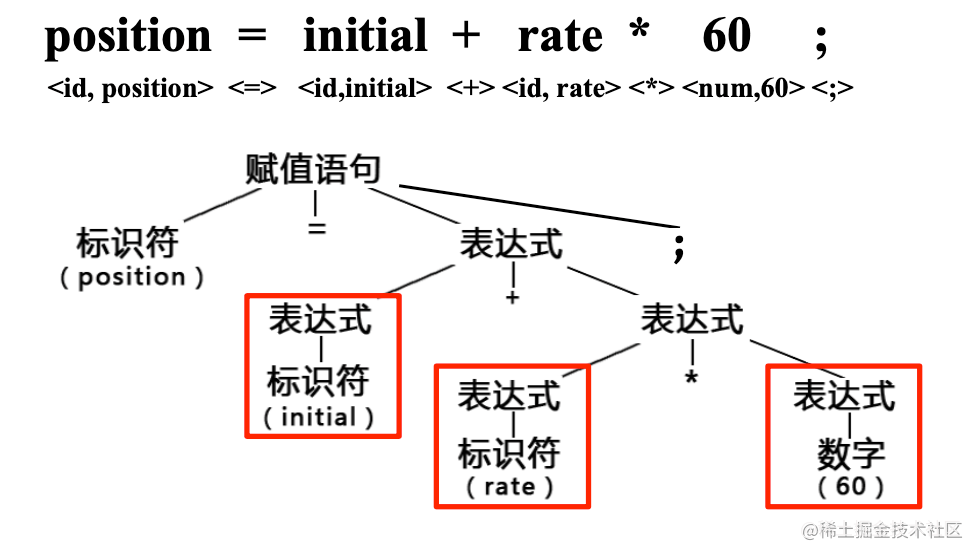
变量声明语句的剖析树:
首先看下变量声明语句的文法( 文法是由一系列规则构成的):
<D>-> <T><IDS>;
<T>-> int | real | char | bool
<IDS>-> id | <IDS>, id
复制代码 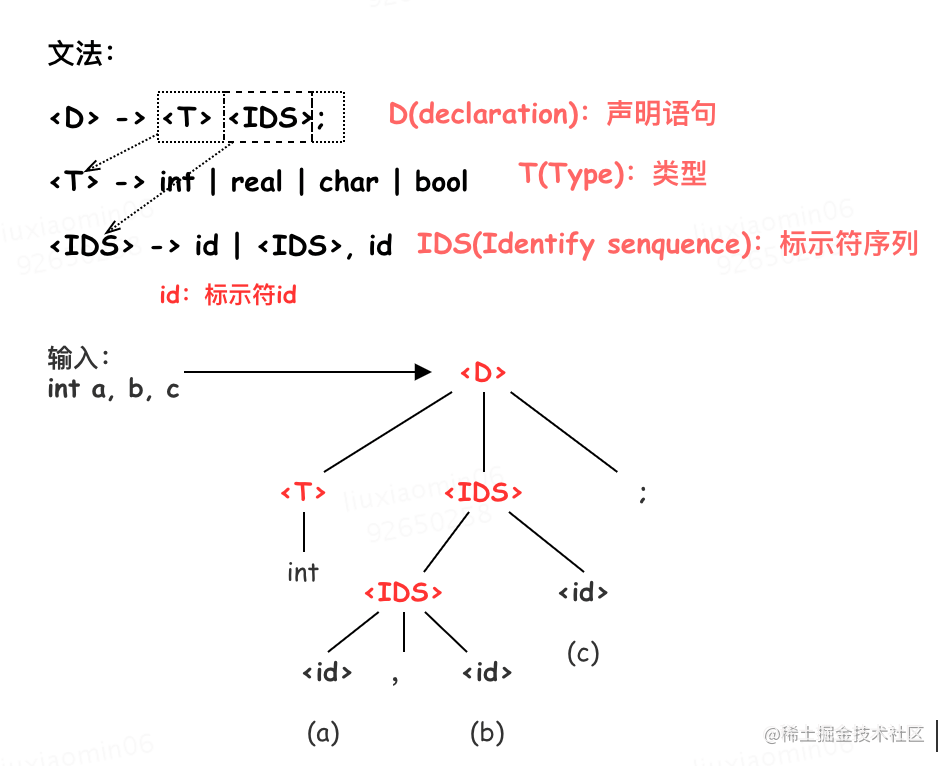
语义剖析
语义的任务主要有两个
一. 搜集标识符的属性信息
- 种属(Kind) :简单变量、复合变量(数组、记载、...)、过程、...
- 类型 (Type) :整型、实型、字符型、布尔型、指针型、...
- 存储位置、长度
- 值
- 作用域
- 参数和返回值信息 ,参数个数、参数类型、参数传送方式、返回值类型、... 语义剖析阶段搜集的标识符的信息都会存储在一个 符号表 里,每个标识符都对应符号表中的 一条记载 ,记载的每个字段记载标识符的每个属性,符号表通常带有一个 字符串表 用来寄存程序中用到的标识符和字符常数, Name 就会被分为两个部分,一部分寄存标识符在字符串表中的起始位置,另一部分用来存储标识符的长度 ,符号表如下图: 除了符号表还有 常量表 (注销各类常量表); 标号表 (注销标号的定义和应用,不常用目的); 入口名表 (注销过程的层号、程序符号表入口等),各种表的生成大部分在词法剖析阶段但是在后面各个阶段都有维护; 中间代码表
二. 语义检查
- 变量或过程 未经声明就运用
- 变量或过程名 重复声明
- 运算重量 类型不匹配
- 操作符与操作数之间的类型不匹配
- 数组下标 不是整数
- 对 非数组变量 运用数组访问操作符
- 对 非过程名 运用过程调用操作符
- 过程调用的**参数类型或数目不匹配 **
- 函数 返回类型 有误
中间代码生成
常用的中间代码表示方式- 三地址码 (Three-address Code):三地址码由相似于汇编言语的指令序列组成,每个指令最多有三个操作数(operand)
- 语法结构树/语法树 (Syntax Trees)
- 逆波兰式
三地址指令的表示:
- 四元式 (Quadruples),(op, y, z, x)
- 三元式 (Triples)
- 间接三元式 (Indirect triples)
下面图中展示了一个中间代码生成的例子 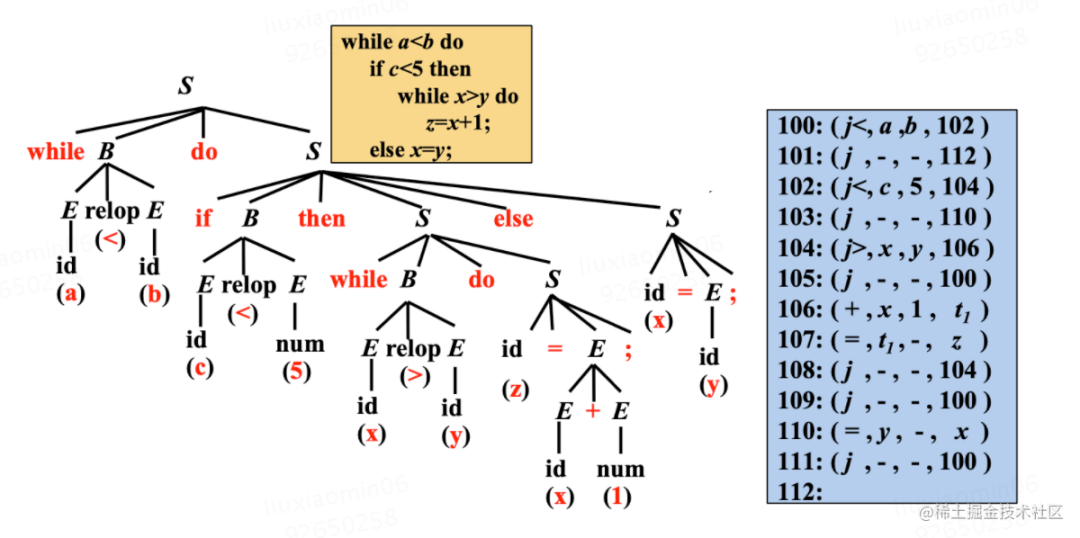
代码优化
对前面生成的中间代码中止加工变换,以便在最后极端产生更为高效的目的代码 , 需求遵照等价变换的准绳,优化的方面包含:公共子表白式的提取、兼并已知量、删除无用语句、循环优化。
目的代码生成
把经过优化的中间代码转化成特定机器上的低级言语
目的代码的方式:
- 汇编指令代码:汇编言语程序,需求经过汇编陈旭汇编后才干运转
- 可重定位指令代码:先将各目的模块衔接起来,肯定变量、常数在主存中的位置,装入主存后才干成为能够运转的绝对指令代码
其他
出错处置假如源程序有错误,编译程序应设法发现错误并讲演给用户。由特地的出错处置程序来完成。错误类型:
- 语法错误:在词法剖析和语法剖析阶段检测出来
- 语义错误:普通在语义剖析阶段检测
- 逻辑错误:不可检测,好比死循环,普通不处置由于没措施在编译阶段检测出来
遍指对源程序或源程序的中间结果从头到尾扫描一次,并做有关的加工处置,生成新的中间结果或目的代码。 遍与阶段的含义毫无关系
多遍扫描: 优点:俭省内存空间,进步目的代码的质量,使编译的逻辑结构明晰。 缺陷:编译时间长。在内存答应的状况下还是遍数尽可能少较好 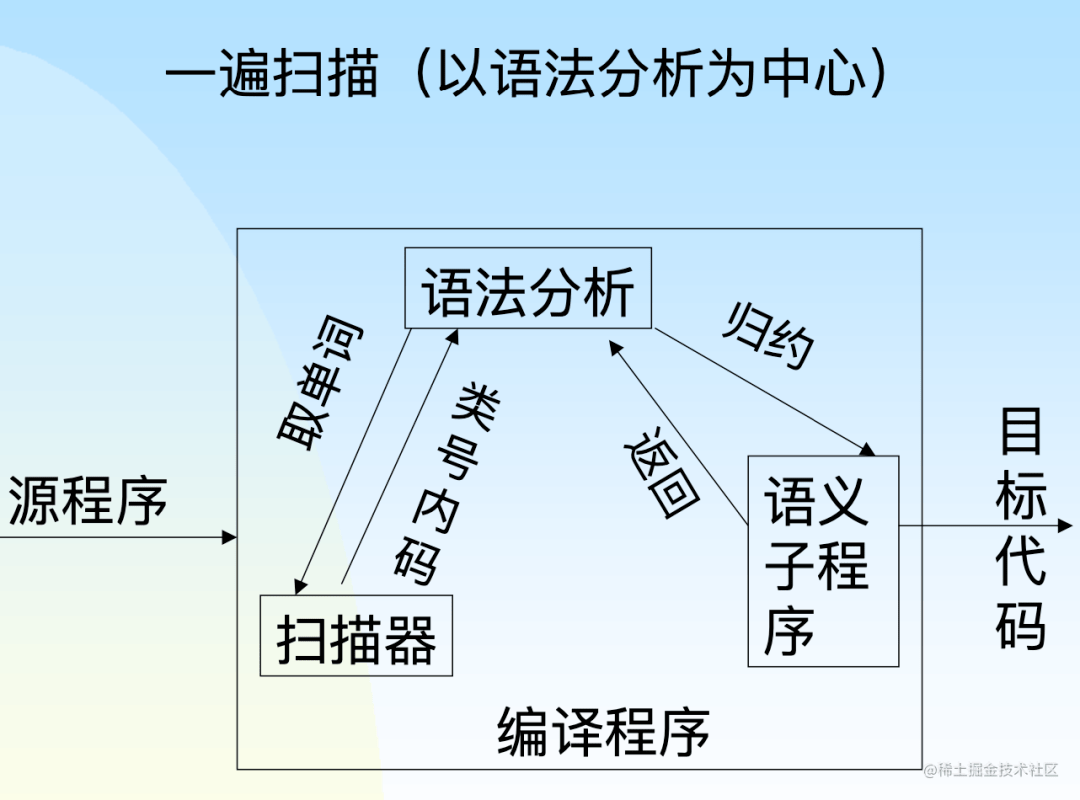
编译程序生成
- 直接用机器言语编写编译程序
- 用汇编言语编写编译程序 ,编译程序中心部分常用汇编言语编写
- 用高级言语编写编译程序 ,这也是普遍采用的措施
- 自编译
- 编译工具 LEX(语法剖析)与YACC(用于自动生成LALR剖析表)
- 移植 (同种言语的编译程序在不同类型的机器之 间移植) 在某机器上为某种言语结构编译程序要控制以下三方面:
- 源言语
- 目的言语
- 编译措施 编译的基础学问就是这些啦,后续会继续深化的学习并记载,喜欢省事点赞哈
—版权声明—
来源:前端小小min,编辑:nhyilin
仅用于学术分享,版权属于原作者。
若有侵权,请联络微信号:Eternalhui或nhyilin删除或修正!
关注公众号了解更多
会员申请 请在公众号内回复“个人会员”或“单位会员
欢送关注中国指挥与控制学会媒体矩阵
CICC官方网站
CICC官方微信公众号
《指挥与控制学报》官网
国际无人系统大会官网
中国指挥控制大会官网
全国兵棋推演大赛
全国空中智能博弈大赛
搜狐号
一点号
| 
 万奢网手机版
万奢网手机版











