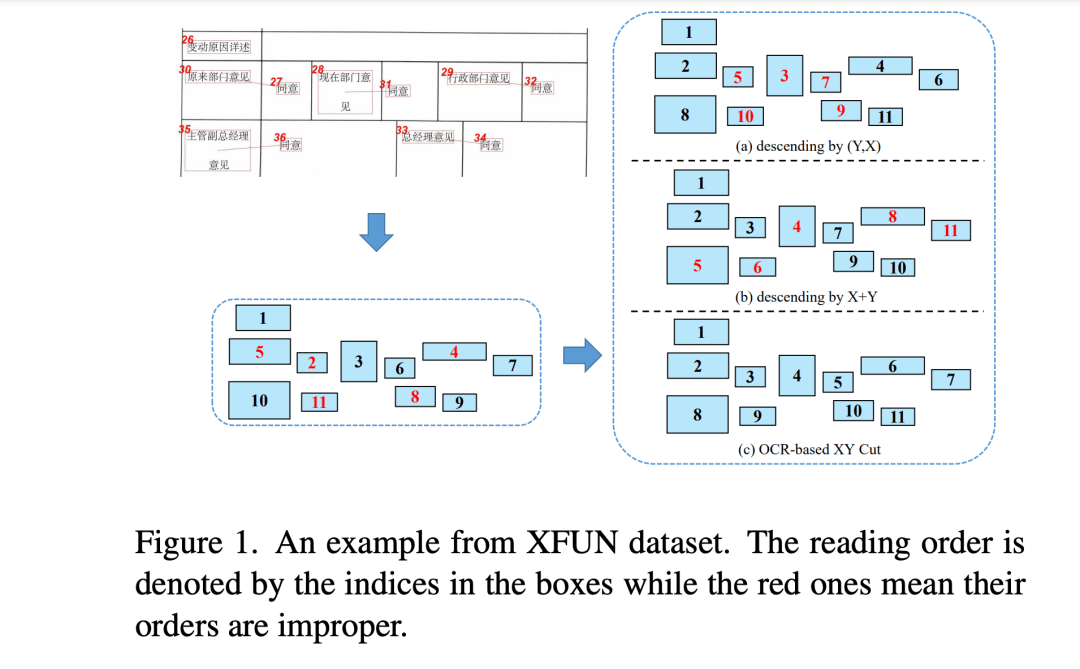
向AI转型的程序员都关注了这个号 最近有很多多模网络用于处置视觉信息丰厚的文档了解(VRDU)。同时用视觉,规划信息和文本embedding。 但是大部分措施在序列中融合位置编码,疏忽了经过OCR工具可能产生的不正确阅读次第。 文章提出XYLayoutLM, 经过Augmented XY Cut的措施来或者正确的阅读次第。 同时文章运用了Dilated Conditional Position Encoding模块去处置不同长度的序列。 引见 LayoutLMv2的2个局限性: 1)需求依托OCR产生的tokens和bbox,没有去探求阅读次第带来的影响。阅读次第关于翻译等问题是很关键的。通常的做法是用位置编码来表示输入次第。作者发现,即便用了位置编码,还是有可能呈现次第错误的状况。
从上图来看,这个30对应的是27,28对应31,29对应33,这个次第是错误的。 2)通常运用固定长度的相对或者绝对位置编码。带来的问题是:不能处置比固定长度长的序列。有运用双线性插值的措施用于位置编码,但是效果不是很好。最近,Conditional Position Encoding(CPE)用于变长的图像分类任务。经过改动输入token到2D的特征,用卷积动态提取部分输入信息。CPE的设计是用于视觉token,不能直接用于1D的文本token。 本文基于LayoutLMv2提出了XYLayoutLM。就是为理处置上面的2局限性。 处置次第问题 传统的经过从上到下,从左到右的次第重排列还是错误。用2种简单的规则: 1)先对Y轴降序排序,再对X轴降序排序。 2)经过Y+X的降序排列。 都错误,从上面的看。最后用XY Cut取得了正确的排序。 处置输入序列变长问题 Dilated Conditional Position Encoding(DCPE)来生成位置编码。 措施 整体概览
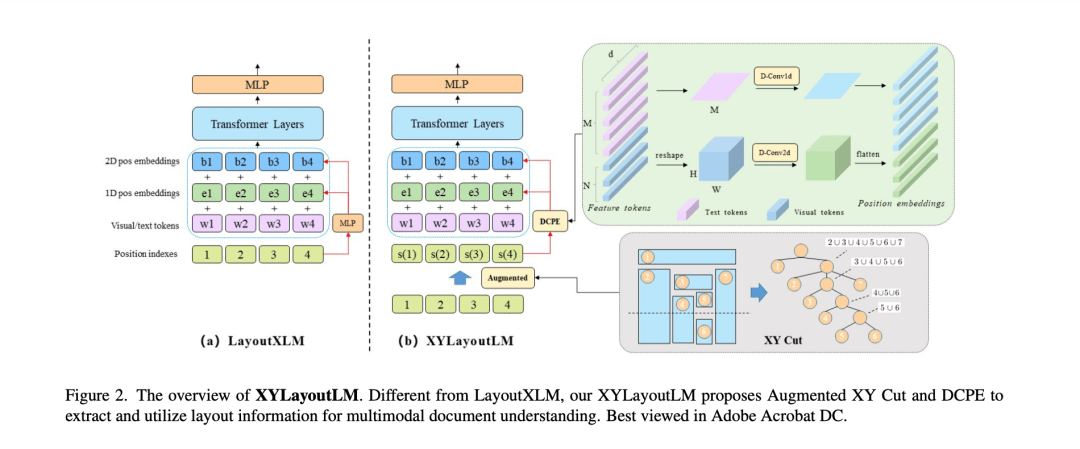
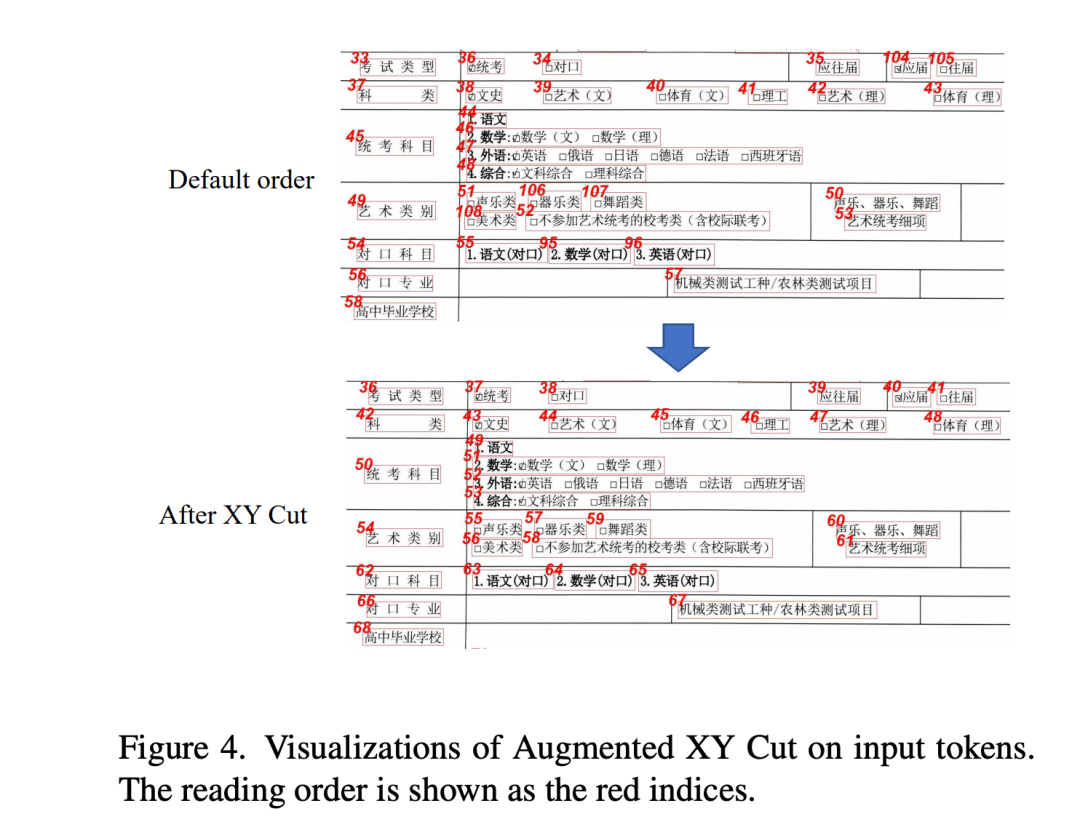
整个模型架构如上图所示。 有图像,文字和文本位置信息作为输入。 视觉信号经过ResNeXt-101提取。经过展开后,和文本信息融合。 2个独立的位置编码,分别是位置编码和bbox编码。 和LayoutXLM的不同就是上面写的次第和位置编码。 LayoutXLM的概览 LayoutXLM有3个输入:文本,图像和规划(位置信息)。 每个输入都经过一个固定长度的MLP层转换成embedding序列。 文本和图像,规划的编码都一同成为了输入编码。 输入编码经过transformer(伴有空间自留意力机制)。 最后,视觉和文本信息经过transformer输出用于文本了解任务。 简单来讲:text, visual, layout embedding -> transformer -> output(用来做各种task) 正确的阅读次第 从直觉来讲,怎样让token box对其和如何垂直水平分割区域。 所以经过,token box的投影来分割,决议阅读次第。先引见投影措施然后引见Augmented XY Cut算法。 经过投影取得直方图 一个框有4个点信息【xmin, ymin, xmax, ymax】。参与OCR提取了K个框。 经过去产生对应的水平和垂直的直方图。对K个直方图求和。 经过直方图的部分最小值来取得应该分开的点(这个很CV的思绪) Augmented XY Cut Algorithm 伪代码
创建一个xy的树,去记载阅读次第。框最为输入,算法会输出对应阅读次第的索引。 我们提出一个数据增强的战略,有个3个参数,x, y, theta. x,y是决议我在这个框是不是要在x轴或者y轴上移动。 假如要移动,会移动theta * x/y个像素。 从一个(-1, 1)的正态散布上随机声从2个值,假如随机值大于x, y 就会移动。 作者设定的参数为0.5, 0.5, theta=5。(觉得就是为了避免直方图算出来的部分最小不精确) Dilated Conditional Position Encoding CPE会先将展平的序列X投影到2D的视觉空间X'。轴卷积层用到X'上产生位置编码E。 最后,位置编码E会展开,参与到token embedding中作为transformer的输入。 但是直接运用CPE会带来性能降落。缘由是: 1)不正确的阅读次第。(经过XY cut处置) 2)有1D的文本token, 不能很好的变到2D空间。 提出Dilated Conditional Position Encoding(DCPE)来处置第二个问题。 用1D的卷积来处置文本的embeding。 需求更大的感受野,好比句子”他是一个十分帅的男生“。他和男生是强相关的。 但是运用3的卷积核是不行的,所以采用了空泛卷积增加感受野。 实验
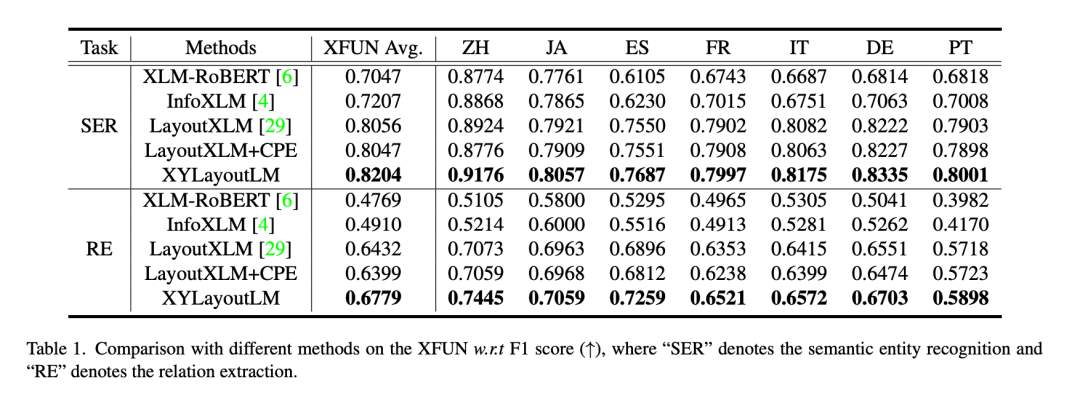
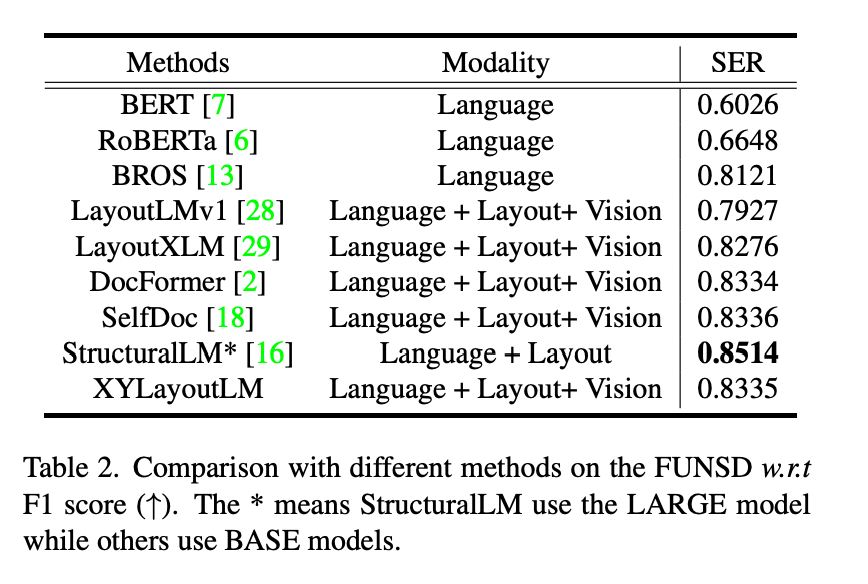
证明XYLayoutLM是很好的。
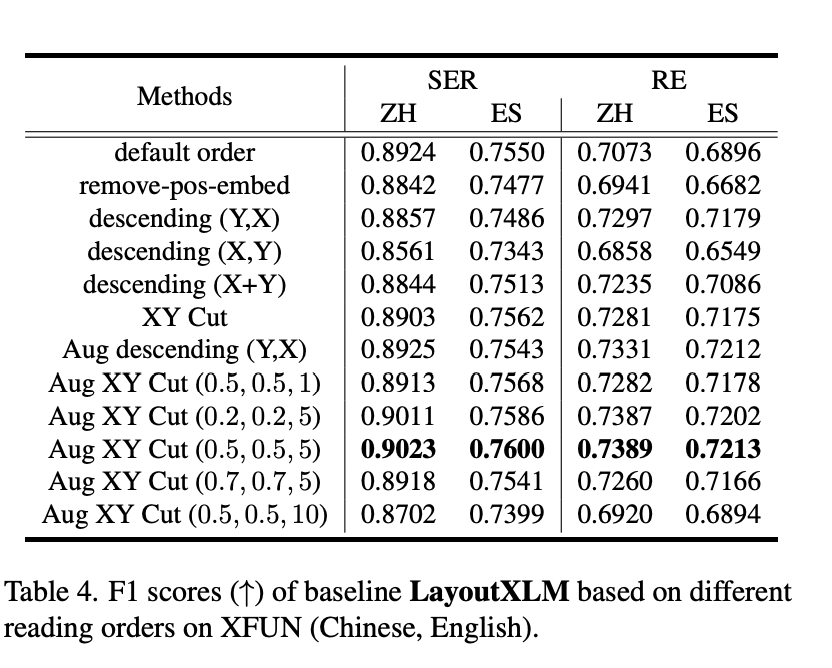
证明这个超参数0.5, 0.5, 5也是最好的。 消融实验,证明每一步的有效性。 可视化留意力 能够发现XYlayoutLM对比layoutLM更有大的attn权重
Augmented XY Cut的有效性, 代码 https://github.com/Sanster/xy-cut 模型性能对比
原文地址 机器学习算法AI大数据技术 搜索公众号添加: datanlp 阅读过本文的人还看了以下文章: TensorFlow 2.0深度学习案例实战 基于40万表格数据集TableBank,用MaskRCNN做表格检测 《基于深度学习的自然言语处置》中/英PDF Deep Learning 中文版初版-周志华团队 【全套视频课】最全的目的检测算法系列解说,浅显易懂! 《美团机器学习理论》_美团算法团队.pdf 《深度学习入门:基于Python的理论与完成》高清中文PDF+源码 《深度学习:基于Keras的Python理论》PDF和代码 特征提取与图像处置(第二版).pdf python就业班学习视频,从入门到实战项目 2019最新《PyTorch自然言语处置》英、中文版PDF+源码 《21个项目玩转深度学习:基于TensorFlow的理论详解》完好版PDF+附书代码 《深度学习之pytorch》pdf+附书源码 PyTorch深度学习快速实战入门《pytorch-handbook》 【下载】豆瓣评分8.1,《机器学习实战:基于Scikit-Learn和TensorFlow》 《Python数据剖析与发掘实战》PDF+完好源码 汽车行业完好学问图谱项目实战视频(全23课) 李沐大神开源《入手学深度学习》,加州伯克利深度学习(2019春)教材 笔记、代码明晰易懂!李航《统计学习措施》最新资源全套! 《神经网络与深度学习》最新2018版中英PDF+源码 将机器学习模型部署为REST API yolo3 检测出图像中的不规则汉字 同样是机器学习算法工程师,你的面试为什么过不了? 前海征信大数据算法:风险概率预测 【Keras】完好完成‘交通标记’分类、‘票据’分类两个项目,让你控制深度学习图像分类 特征工程(一) 特征工程(二) :文本数据的展开、过滤和分块 特征工程(三):特征缩放,从词袋到 TF-IDF 特征工程(四): 类别特征 特征工程(五): PCA 降维 特征工程(六): 非线性特征提取和模型堆叠 特征工程(七):图像特征提取和深度学习 如何应用全新的决策树集成级联合构gcForest做特征工程并打分? Machine Learning Yearning 中文翻译稿 蚂蚁金服2018秋招-算法工程师(共四面)经过 全球AI应战-场景分类的竞赛源码(多模型融合) 斯坦福CS230官方指南:CNN、RNN及运用技巧速查(打印珍藏) 中科院Kaggle全球文本匹配竞赛华人第1名团队-深度学习与特征工程 不时更新资源 深度学习、机器学习、数据剖析、python 搜索公众号添加: datayx |

 万奢网手机版
万奢网手机版
官网微博:万奢网服务平台